Exploring Question-Specific Rewards for Generating Deep Questions
Abstract
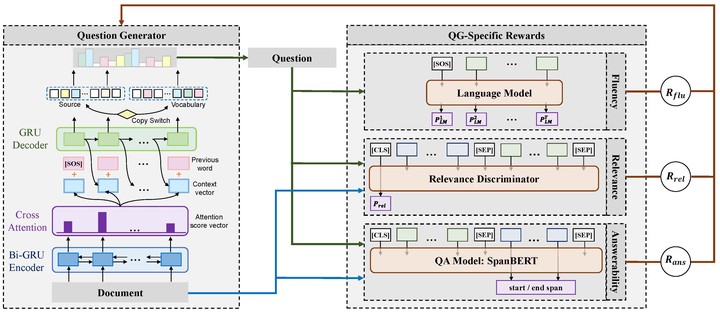
Recent question generation (QG) approaches often utilize the sequence-to-sequence framework (Seq2Seq) to optimize the log-likelihood of ground-truth questions using teacher forcing. However, this training objective is inconsistent with actual question quality, which is often reflected by certain global properties such as whether the question can be answered by the document. As such, we directly optimize for QG-specific objectives via reinforcement learning to improve question quality. We design three different rewards that target to improve the fluency, relevance, and answerability of generated questions. We conduct both automatic and human evaluations in addition to a thorough analysis to explore the effect of each QG-specific reward. We find that optimizing question-specific rewards generally leads to better performance in automatic evaluation metrics. However, only the rewards that correlate well with human judgement (e.g., relevance) lead to real improvement in question quality. Optimizing for the others, especially answerability, introduces incorrect bias to the model, resulting in poor question quality.