Automatically Correcting Large Language Models: Surveying the landscape of diverse self-correction strategies
Abstract
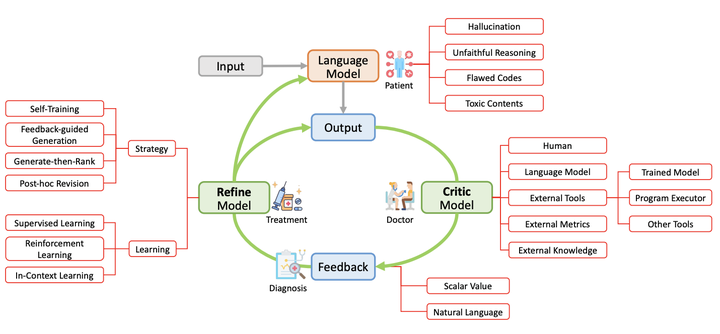
Large language models (LLMs) have demonstrated remarkable performance across a wide array of NLP tasks. However, their efficacy is undermined by undesired and inconsistent behaviors, including hallucination, unfaithful reasoning, and toxic content. A promising approach to rectify these flaws is self-correction, where the LLM itself is prompted or guided to fix problems in its own output. Techniques leveraging automated feedback – either produced by the LLM itself or some external system – are of particular interest as they are a promising way to make LLM-based solutions more practical and deployable with minimal human feedback. This paper presents a comprehensive review of this emerging class of techniques. We analyze and taxonomize a wide array of recent work utilizing these strategies, including training-time, generation-time, and post-hoc correction. We also summarize the major applications of this strategy and conclude by discussing future directions and challenges.